Every normal matrix ${\bf A}\in \mathbb{C}^{d\times d}$ admits a
spectral decomposition of the form (Horn and Johnson 2013; Axler 2015)
\({\bf A}= \sum_{j=1}^{d} \lambda_{j} {\bf u}^{(j)} \big({\bf u}^{(j)})^{H} \nonumber \\\)
with an orthonormal basis ${\bf u}^{(1)},\ldots,{\bf u}^{(d)}$.
{#fig:eigenvectors-length_dict
width=”80%”}
Each basis element ${\bf u}^{(j)}$ is an eigenvector of ${\bf A}$ with
corresponding eigenvalue $\lambda_{j}$, for $j=1,\ldots,d$.
Horn, R. A., and C. R. Johnson. 2013. Matrix Analysis. 2nd ed. New
York, NY, USA: Cambridge Univ. Press.
📚 This explanation is part of the Aalto Dictionary of Machine Learning —
an open-access multi-lingual glossary developed at Aalto University to support
accessible and precise communication in ML.
The pmf of a discrete random variable (RV) $x$ is a function
$p^{(x)}\left(\cdot\right): \mathcal{X}\rightarrow [0,1]$ that assigns
to each possible value $x’ \in \mathcal{X}$ of the random variable (RV)
$x$ the probability
$p^{(x)}\left(x’\right) = \mathbb{P}\left(x’ = x\right)$ (Papoulis and
Pillai 2002). Fig. 1{reference-type=”ref”
reference=”fig_pmf_dict”} illustrates the pmf of a discrete random
variable (RV) $x$.
{#fig_pmf_dict
width=”80%”}
A pmf always satisfies
$\sum_{x’ \in \mathcal{X}} p^{(x)}\left(x’\right) = 1$. We can view a
pmf as representing a collection of (sufficiently long) datasets. This
collection contains any $\mathcal{D}= {x^{(1)}, \,\ldots, \,x^{(m)}}$,
with the relative frequencies of every value $x’ \in \mathcal{X}$ being
close to the corresponding pmf value $p^{(x)}\left(x’\right)$,
\(\frac{\big|r\in \{1,\,\ldots,\,m\}: x^{(r)}= x' \big|}
{m} \approx p^{(x)}\left(x'\right).\) Note that requiring relative
frequencies to be close to the probability mass function (pmf) values
implies that the empirical entropy of such a dataset is close to the
entropy of the probability mass function (pmf)
$p^{(x)}\left(\cdot\right)$. Information theory refers to the collection
of such datasets as the typical set corresponding to the probability
mass function (pmf) $p^{(x)}\left(\cdot\right)$ (Cover and Thomas 2006).
A main result of information theory states that a dataset generated by
independent and identically distributed (i.i.d.) sampling from
$p^{(x)}\left(\cdot\right)$ belongs, with high probability, to the
typical set with respect to $p^{(x)}\left(\cdot\right)$ (Cover and
Thomas 2006, Th. 3.1.2).
See also: random variable (RV), probability, probability distribution,
probabilistic model.
Cover, T. M., and J. A. Thomas. 2006. Elements of Information Theory.
2nd ed. Hoboken, NJ, USA: Wiley.
Papoulis, A., and S. Unnikrishna Pillai. 2002. Probability, Random
Variables, and Stochastic Processes. 4th ed. New York, NY, USA:
McGraw-Hill Higher Education.
📚 This explanation is part of the Aalto Dictionary of Machine Learning —
an open-access multi-lingual glossary developed at Aalto University to support
accessible and precise communication in ML.
Consider a multi-class classification problem with feature space
$\mathcal{X}$ and finite label space $\mathcal{Y}= {1,\ldots,k}$. A
data point with feature vector ${\bf x}$ is represented by a probability
mass function (pmf)
${\bf y}= (\truelabel_{1},\ldots,\truelabel_{k})^{T}$
over $\mathcal{Y}$, where $\truelabel_{c}$ denotes the probability that
the label of a randomly chosen data point with feature vector ${\bf x}$,
equals $c$. A hypothesis $h({\bf x})$ outputs a predicted probability
mass function (pmf) $\hat{{\bf y}} = (\predictedlabel_{1},\ldots,
\predictedlabel_{k})^{T}$. The associated cross-entropy loss is (Cover
and Thomas 2006) \(\nonumber
L\left(({\bf x},\hat{{\bf y}}),h\right)
:=- \sum_{c=1}^{k}
\truelabel_{c}\,\log \predictedlabel_{c}.\) The cross-entropy loss
quantifies the dissimilarity between the true probability mass function
(pmf) ${\bf y}$ and the predicted probability mass function (pmf)
$\hat{{\bf y}}$. It is also a measure for the expected number of bits
required to encode labels drawn from the true probability mass function
(pmf) ${\bf y}$ when using a coding scheme optimized for the predicted
probability mass function (pmf) $\hat{{\bf y}}$ (Cover and Thomas
2006). Note. For binary classification (with $k= 2$), the cross-entropy
loss reduces to the logistic loss when employing a parametric model with
model parameters ${\bf w}$ such that
$\predictedlabel_{2}/\predictedlabel_{1}
= \exp({\bf w}^{T}{\bf x})$. Note that the representation
[equ_log_loss_gls_dict]{reference-type=”eqref”
reference=”equ_log_loss_gls_dict”} of logistic loss requires encoding
the label space ${1,2}$ by the values $-1$ and $1$.
See also: classification, logistic loss, probability mass function
(pmf).
Cover, T. M., and J. A. Thomas. 2006. Elements of Information Theory.
2nd ed. Hoboken, NJ, USA: Wiley.
📚 This explanation is part of the Aalto Dictionary of Machine Learning —
an open-access multi-lingual glossary developed at Aalto University to support
accessible and precise communication in ML.
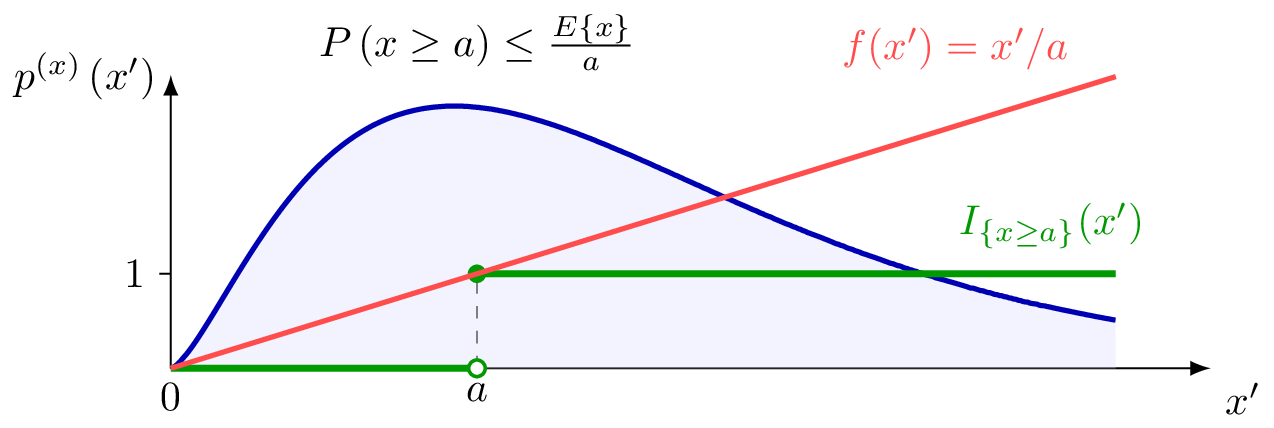
Consider a real-valued non-negative random variable (RV) $x$ for which
the expectation $\mathbb{E} { x}$ exists. Markov’s inequality provides
an upper bound on the probability $\mathbb{P}\left(x\geq a\right)$ that
$x$ exceeds a given positive threshold $a>0$. In particular,
\(\mathbb{P}\left(x \geq a\right) \leq \frac{\mathbb{E} \{ x\}}{a} \qquad \mbox{ holds for any } a > 0.
\label{eq:markovsinequality_dict}\)
This inequality can be verified by
noting that $\mathbb{P}\left(x \geq a\right)$ is the expectation
$\mathbb{E} {g(x)}$ with the function
\(g: \mathbb{R} \rightarrow \mathbb{R}: x' \mapsto \mathbb{I}_{\{x \geq a\}}(x').\)
As illustrated in the Figure below, for any positive $a>0$,
\(g(x') \leq x'/a \mbox{ for all } x' \in \mathbb{R}.\) This obvious inequality
implies Markov’s inequality via the monotonicity of the Lebesgue integral (Folland 1999, 50).
See also: expectation, probability, concentration inequality.
Folland, Gerald B. 1999. Real Analysis: Modern Techniques and Their
Applications. 2nd ed. New York, NY, USA: Wiley.
📚 This explanation is part of the Aalto Dictionary of Machine Learning —
an open-access multi-lingual glossary developed at Aalto University to support
accessible and precise communication in ML.
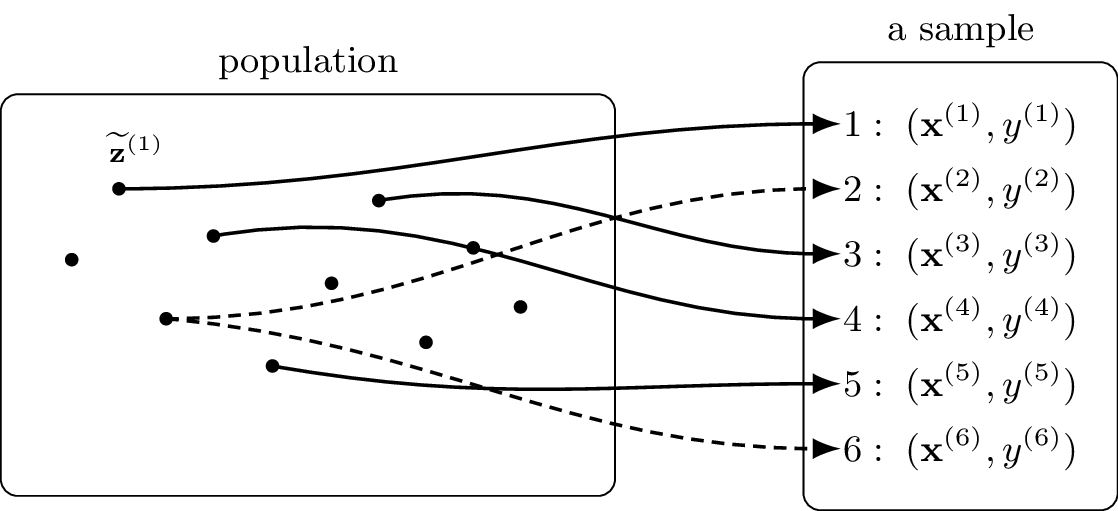
In the context of machine learning (ML), a sample is a finite sequence
(of length $m$) of data points, ${\bf z}^{(1)}, \ldots, {\bf z}^{(m)}$.
The number $m$ is called the sample size. Empirical risk minimization
(ERM)-based methods use a sample to train a model (or learn a
hypothesis) by minimizing the average loss (the empirical risk) over
that sample. Since a sample is defined as a sequence, the same data
point may appear more than once. By contrast, some authors in statistics
define a sample as a set of data points, in which case duplicates are
not allowed (Everitt and Skrondal 2010; Upton and Cook 2014). These two
views can be reconciled by regarding a sample as a sequence of
feature–label pairs, $\left( {\bf x}^{(1)},y^{(1)} \right), \ldots,
\left( {\bf x}^{(m)},y^{(m)} \right)$. The $r$-th pair consists of the
features ${\bf x}^{(r)}$ and the label $y^{(r)}$ of an unique underlying
data point $\widetilde{{\bf z}}^{(r)}$. While the underlying data points
$\widetilde{{\bf z}}^{(1)},\ldots,\widetilde{{\bf z}}^{(m)}$ are unique,
some of them can have identical features and labels.
A sample viewed as a finite sequence. Each element of this
sample consists of the feature vector and the label of a data point from
an underlying population. The same data point may occur more than once
in the sample.
For the analysis of machine learning (ML) methods, it is common to
interpret (the generation of) a sample as the realization of a
stochastic process indexed by ${1,\ldots,m}$. A widely used assumption
is the independent and identically distributed assumption
(i.i.d. assumption), where sample elements
$\left( {\bf x}^{(r)},y^{(r)} \right)$, for $r=1,\ldots,m$, are
independent and identically distributed (i.i.d.) random variables (RVs)
with a common probability distribution.
See also: dataset, sequence, independent and identically distributed
assumption (i.i.d. assumption).
Everitt, B. S., and A. Skrondal. 2010. The Cambridge Dictionary of
Statistics. 4th ed. Cambridge, U.K.: Cambridge Univ. Press.
Upton, Graham, and Ian Cook. 2014. A Dictionary of Statistics. 3rd ed.
Oxford Univ. Press.
📚 This explanation is part of the Aalto Dictionary of Machine Learning —
an open-access multi-lingual glossary developed at Aalto University to support
accessible and precise communication in ML.
TL;DR: Generalization is a model’s ability to make accurate predictions on new, unseen data
after training. This post explains probabilistic and robustness-based views of generalization, including
empirical risk minimization (ERM) and perturbation tests.
Generalization refers to the ability of a machine learning (ML)
method trained on a training set to make accurate predictions on new, unseen data.
This is a central goal of ML and AI: to learn patterns that extend beyond the data
available during training.
Most ML systems use empirical risk minimization (ERM) to
learn a hypothesis $\hat{h} \in \mathcal{H}$ by minimizing
the average loss over a training set of data points
${\bf z}^{(1)}, \ldots, {\bf z}^{(m)}$, denoted as $\mathcal{D}^{(\rm train)}$. However, success on the
training set does not guarantee success on unseen data—this discrepancy is the challenge of generalization.
To study generalization mathematically, we often assume a probabilistic model for data generation, such as the
i.i.d. assumption. That is, we interpret data points
as independent random variables (RVs) with an identical probability distribution $p({\bf z})$. This distribution,
while unknown, allows us to define the risk of a trained model $\hat{h}$ as the expected loss:
The difference between risk $\bar{L}(\hat{h})$ and empirical risk $\widehat{L}(\hat{h}|\mathcal{D}^{(\rm train)})$ is
called the generalization gap. Tools from probability theory—such as concentration inequalities and uniform
convergence—can be used to bound this gap under specific conditions (Shalev-Shwartz and Ben-David 2014).
Generalization Without Probability
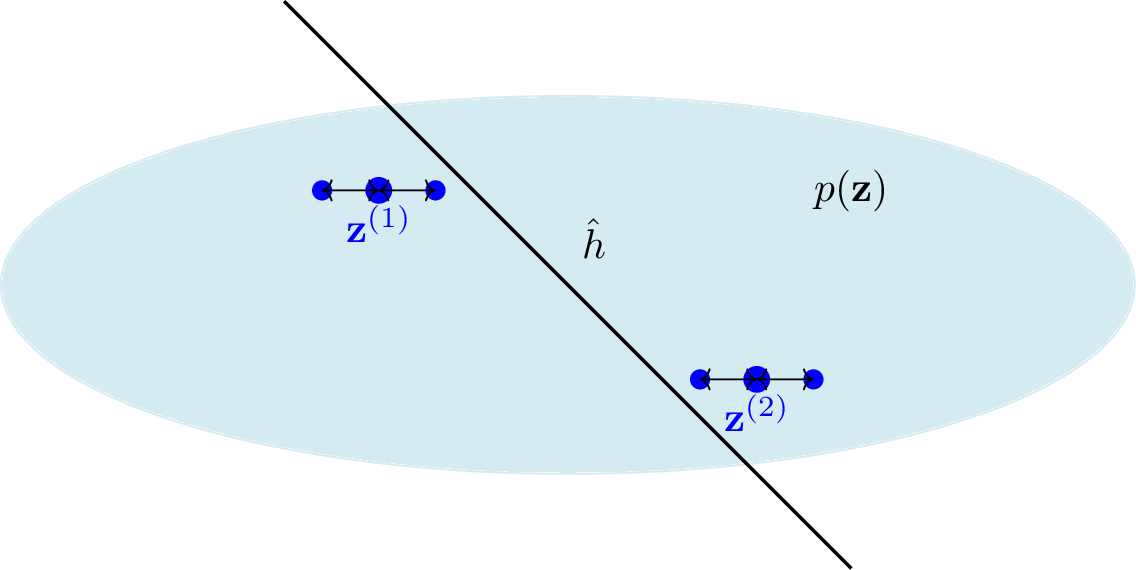
Probability theory is one way to study generalization, but not the only one. Another approach uses perturbations
to the training data. The idea is simple: a good model $\hat{h}$ should be robust. Its prediction $\hat{h}({\bf x})$
should not change much if we slightly modify the input ${\bf x}$ of a data point ${\bf z}$.
For example, an object detector trained on smartphone photos should still detect the object if a few random pixels are masked (Su, Vargas, and Sakurai 2019). Similarly, it should produce consistent predictions if the object is rotated (Mallat 2016).
Two data points ${\bf z}^{(1)},{\bf z}^{(2)}$ used as a training set to learn a hypothesis $\hat{h}$ via ERM. Generalization
can be evaluated using either the i.i.d. assumption or deterministic perturbations of the training data.
❓ Frequently Asked Questions
What is generalization in machine learning?
Generalization is a model’s ability to make accurate predictions on new, unseen data after training on a known dataset.
What causes poor generalization?
Overfitting, data imbalance, and overly complex models often lead to poor generalization.
Can we study generalization without probability theory?
Yes. Deterministic approaches like robustness testing with perturbations offer a complementary perspective.
What is the generalization gap?
It’s the difference between the empirical loss on training data and the expected loss on unseen data.
📚 References
Mallat, Stéphane. 2016. “Understanding Deep Convolutional Networks.” Philosophical Transactions of the Royal Society A 374 (2065): 20150203. https://doi.org/10.1098/rsta.2015.0203
Shalev-Shwartz, S., and S. Ben-David. 2014. Understanding Machine Learning: From Theory to Algorithms.
Cambridge University Press.
Su, J., D. V. Vargas, and K. Sakurai. 2019. “One Pixel Attack for Fooling Deep Neural Networks.” IEEE Transactions on Evolutionary Computation 23 (5): 828–841. https://doi.org/10.1109/TEVC.2019.2890858
📚 This explanation is part of the Aalto Dictionary of Machine Learning —
an open-access multilingual glossary developed at Aalto University to support accessible and precise communication in ML.
This makes it a robust alternative to the mean when data includes outliers.
📚 This explanation is part of the Aalto Dictionary of Machine Learning —
an open-access multi-lingual glossary developed at Aalto University to support
accessible and precise communication in ML.
It is almost 10 years since I started on the tenure track at Aalto University (Finland).
From the very beginning, I had the unique opportunity to contribute to shaping and
enhancing the Machine Learning curriculum at our university.
Over the past decade, I have designed and implemented core courses for the
machine learning curricula at Aalto University at both the Bachelor and
Master levels. These courses have not only benefited degree-seeking students
but also reached beyond, offering opportunities for adult learners through
the Finnish Institute of Technology (FITech.io).
Developing a machine learning curriculum is iterative. A curriculum
needs to balance theoretical foundations with practical applications.
Three core principles have driven my approach:
Practical Relevance: The design of a course starts with writing down the learning goals. These goals include very concrete skills and core theoretical concepts. It can be effective to motivate and demonstrate theoretical concepts by every-day life applications.
Student-Centric Design: I view student feedback as important as peer reviews for my research papers. Similar to the peer review process of journals I prepare response letters to explain how sutdent feedback has been taken into account.
Collaboration & Inclusivity: By working with partners like FITech and Unite!, the curriculum
extends beyond Aalto University, offering access to a broader learning community, including adult
learners and international students.
These principles foster a curriculum that grows alongside advancements in machine learning and AI.
📣 Testimonial from a Co-Lecturer
“…I like to take the opportunity to express that, in my opinion, Alex has generated a very strong, didactically excellent course with a good focus on the necessary basic concepts and principles. It mixes theory and focused exercises with a machine learning project in which students grow while applying their learned knowledge on actual data. From last year to this year, the course has been further improved significantly by rigorously addressing the feedback collected by the students.”
📣 Testimonial from VP Education of Aalto University
“…I learnt to know Alex in 2015 in my earlier role, VP Education of Aalto University, when Alex joined the faculty of Aalto University School of Science as an Assistant Professor. My first impression was his dedication and passion to create powerful learning experiences for all his students. It was no surprise that the student feedback was extremely positive from day one…”
🌐 Looking Ahead
As the field of machine learning evolves, so must our university curricula.
My current focus is on integrating more content related to explainable AI (XAI), federated learning,
and trustworthy AI. These are areas of growing importance in both academia
and industry. We need to equip students with required skills to build human-centered
and trustworthy AI.
There is also growing demand for education in legal literacy in AI and data-driven
technologies. We need to reshape tech-focused curricula in order to cover the
intersection of AI and law. This includes courses that provide students with an
understanding of key legal concepts such as data privacy regulations (like GDPR),
AI ethics, and accountability frameworks. These additions will enable students to
grasp the legal and ethical implications of deploying AI systems, which is increasingly
essential for roles in both academia and industry.
An essential requirement for trustworthy artificial intelligence (AI) is its explainability to human users [1].
One principled approach to explainable AI is via the concept of simulatability: Roughly speaking,
the better a specific human user can anticipate the behaviour of an AI, the more explainable it
is (to this particular user).
In the context of machine learning (ML), which is at the core of many current AI systems, we can formalize
explainability by the notion of a user signal [2]. The user signal is some subjective characteristic of
data points. We can think of a user signal as a specific feature that a user assigns to a data point.
We denote the user signal u(x) as a function of the raw features x of a data point.
In this blog post, we explore explainable ML using a straightforward weather prediction example based
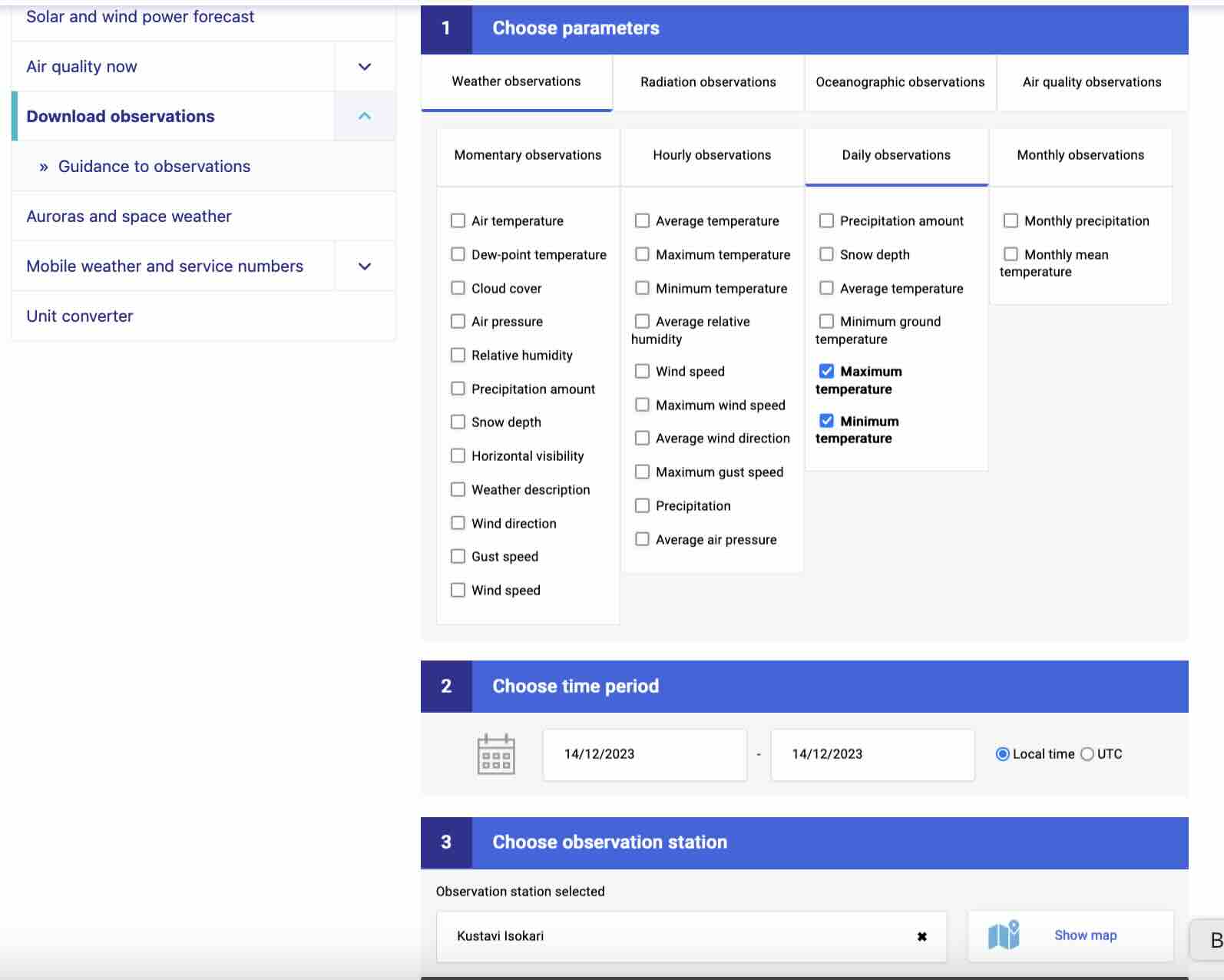
on real-world data from the Finnish Meteorological Institute (FMI). The data was recorded at a FMI weather
station near Kustavi Isokari
We aim to create an explainable weather prediction model that aligns with human
intuition. Some user signal models this intuition.
Predicting Maximum Daytime Temperature with Explainable AI: A Real-World Example
Given historical weather data, we want to learn to predict the maximum daytime temperature (maxtemp)
solely from the minimum daytime temperature (mintemp). To this end, we first download weather recordings
from the FMI website
into a csv file KustaviIsokari.csv. The following code snippet reads in the downloaded data from the csv file
and stores their features and labels in the variables X and y, respectively [3],
# Load the data from the CSV file
file_path="KustaviIsokari.csv"# Replace with the actual file path
data=pd.read_csv(file_path)# Extract relevant columns
data=data[["Maximum temperature [°C]","Minimum temperature [°C]"]]# Randomly select a specified number of data points
num_data_points=15# Specify the number of data points to select
data=data.sample(n=num_data_points,random_state=42)# build feature matrix (with one column in this case) and label vector
X=data[["Minimum temperature [°C]"]]y=data["Maximum temperature [°C]"]
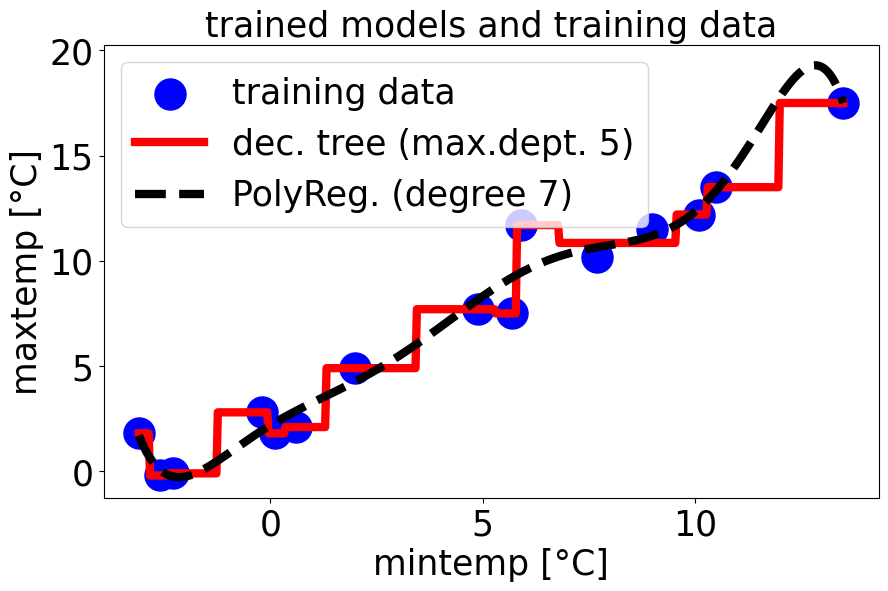
Using the features X and labels y, we next train two basic ML models:
a decision tree regressor and a polynomial regressor [4].
# Train a Decision Tree Regressor
maxdep=3dt_model=DecisionTreeRegressor(random_state=42,max_depth=maxdep)dt_model.fit(X,y)# Train a Polynomial Regression model
poly_degree=7# Specify the degree of the polynomial
poly_features=PolynomialFeatures(degree=poly_degree)X_train_poly=poly_features.fit_transform(X)poly_model=LinearRegression()poly_model.fit(X_train_poly,y)
We then plot the predictions of the trained models along with training data.
How do you like the behaviour of the trained models? Both models predict increasing maxtemp for
decreasing mintemp for very cold days (towards the left in the above plot). Moreover, the polynomial
regressor predicts decreasing maxtemp with increasing mintemp for warm days (towards the right in
the above plot). Predicting a decreasing maxtemp for increasing mintemp is counter-intuitive.
Enhancing Explainability in AI with Data Augmentation
It seems reasonable to assume that higher min. temps. result in higher max.temps.
We can exploit this intuition (or user knowledge) to regularize the above model training
via data augmentation [5]:
For each original data point, with mintemp x and maxtemp y, we add two
additional data points:
one with mintemp x+1 and maxtemp y+1
one with mintemp x-1 and maxtemp y-1
Note that this data augmentation strategy can be interpreted as
a specific choice for a user signal u(x). In particular, the user signal
satisfies u(x+1)=y+1 and u(x-1)=y-1 for any data point (x,y)
in the original training set.
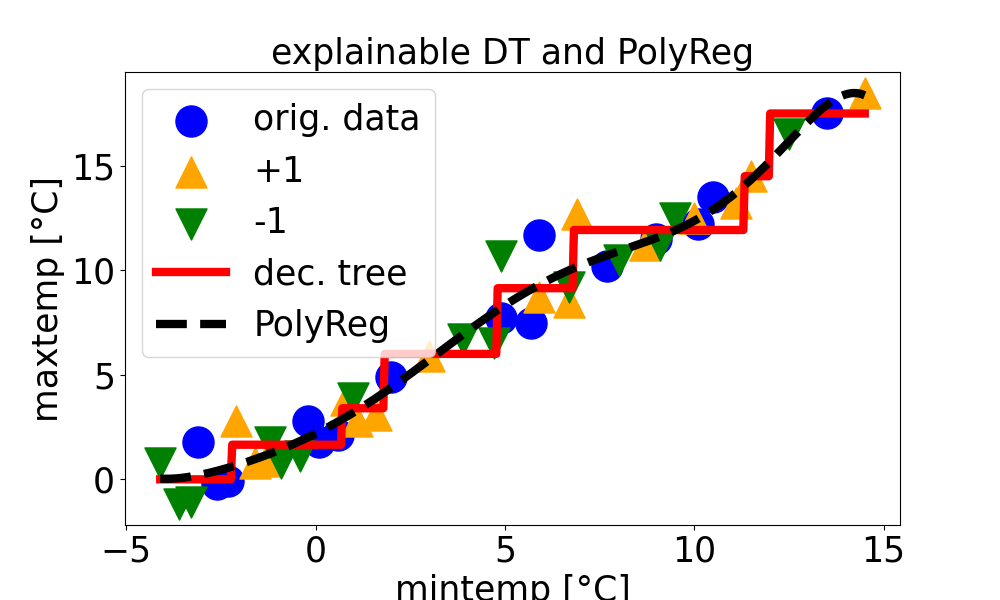
The following code snippet implements the above data augmentation and
then retrains the decision tree and polynomial regression model.
# Augment the training set
augmented_data=data.copy()augmented_data["Minimum temperature [°C]"]=data["Minimum temperature [°C]"]+1augmented_data["Maximum temperature [°C]"]=data["Maximum temperature [°C]"]+1augmented_data_minus=data.copy()augmented_data_minus["Minimum temperature [°C]"]=data["Minimum temperature [°C]"]-1augmented_data_minus["Maximum temperature [°C]"]=data["Maximum temperature [°C]"]-1# Combine original and augmented data
data_augmented=pd.concat([data,augmented_data,augmented_data_minus],ignore_index=True)# Split augmented data into predictors and target
X_augmented=data_augmented[["Minimum temperature [°C]"]]y_augmented=data_augmented["Maximum temperature [°C]"]# Train a Decision Tree Regressor
dt_model=DecisionTreeRegressor(random_state=42,max_depth=3)dt_model.fit(X_augmented,y_augmented)# Train a Polynomial Regression model
poly_degree=7# Specify the degree of the polynomial
poly_features=PolynomialFeatures(degree=poly_degree)X_train_poly=poly_features.fit_transform(X_augmented)poly_model=LinearRegression()poly_model.fit(X_train_poly,y_augmented)
And here are the resulting trained DT and polynomial regressor, along with the
original and augmented data points. Carefully note that the trained models
now respect my (your?) intuition that maxtemp is monotonically increasing
with mintemp. In this sense, these models can be considered more explainable
than the trained models without data augmentation.
References and Further Reading on Explainable AI
High-Level Expert Group on Artificial Intelligence. (2019). Ethics guidelines for trustworthy AI. European Commission. click here↩
A. Jung and P. H. J. Nardelli, “An Information-Theoretic Approach to Personalized Explainable Machine Learning,” in IEEE Signal Processing Letters, vol. 27, pp. 825-829, 2020, doi: 10.1109/LSP.2020.2993176. ↩
You can find a Python script to reproduce the presented results here: click me↩
A. Jung, Machine Learning: The Basics, Springer, 2022. https://doi.org/10.1007/978-981-16-8193-6 ↩
L. Zhang, G. Karakasidis, A. Odnoblyudova, et al., “Explainable empirical risk minimization,” in Neural Comput & Applic 36, 3983–3996 (2024). https://doi.org/10.1007/s00521-023-09269-3 ↩
Alex teaching a class during a Machine Learning course at Aalto University.
In recent years, there’s been a troubling trend in higher education:
the gradual transformation of taxpayer-funded universities into profit-driven
entities. Under the guise of global competitiveness, many institutions are
becoming little more than research factories, churning out papers and
funding applications to sustain bloated systems while neglecting their
core missions—education and the public good.
The Commodification of Knowledge
Taxpayer-funded universities are pillars of society. They are meant to be sanctuaries of learning, innovation,
and critical thinking. But as financial pressures mount and market-oriented policies take hold, the focus has
shifted alarmingly.
Academic success is increasingly measured by metrics—the number of publications, grant money secured,
or the size of international collaborations (Hicks et al., 2015). These metrics prioritize quantity over quality,
reducing groundbreaking research to a box-ticking exercise. Worse, they incentivize universities to exploit
their researchers, burden faculty with administrative tasks, and disregard the well-being of students.
Who Benefits? Not the Taxpayer.
During my academic career, I have observed a growing trend (or fashion) at universities to funnel resources
into large, well-funded research groups. These groups act like private companies within the university ecosystem,
hoarding resources and focusing on high-revenue projects. While such groups rake in grants, smaller departments
and programs suffer budget cuts, and students face higher tuition fees with diminishing returns in terms of education quality (Slaughter & Rhoades, 2004).
Taxpayers fund these institutions expecting them to educate future generations and contribute to society—not to turn into profit centers that primarily serve private interests.
The Human Cost of Overproduction
This obsession with profitability also has devastating consequences for academia’s human core:
Faculty Burnout: Professors are stretched thin and expected to churn out high-quality publications and secure
external funding (Shanafelt et al., 2015). This leaves little time for mentorship, directly impacting the next generation of scholars.
Precarious Positions: Early-career researchers typically face insecure, short-term contracts, jumping from project to
project without stable employment (Chisholm, 2023).
Student Neglect: Overcrowded classrooms, reduced course offerings, and a lack of individual attention are the
norm as resources are funneled into research output rather than teaching quality (Ingleby, 2021).
A Call for Change
It’s time to reclaim universities as public institutions dedicated to serving society. Here are three steps we must take:
Prioritize Education: Public funding must be used to ensure high-quality education instead of
funnelling tax-payer money into expanding research portfolios.
Value Impact Over Metrics: Shift the focus away from publication counts and grant amounts. Reward meaningful research
that directly benefits society, rather than research done for the sake of securing the next funding cycle (Moher et al., 2018).
Protect Academic Freedom: Universities must provide faculty with the freedom to pursue research and teaching without the
relentless pressure to commercialize or industrialize their work (Altbach et al., 2020).
A University for the People
Taxpayer-funded universities are a collective investment in the future. They should serve the public, not function as cash cows
for a select few. Education and research are not commodities—they are the bedrock of a thriving, equitable society. Let’s demand better.
Let’s ensure that universities remain places of inspiration, innovation, and integrity—not profit.
References:
Hicks, D., Wouters, P., Waltman, L., de Rijcke, S., & Rafols, I. (2015). Bibliometrics: The Leiden Manifesto for research metrics. Nature, 520(7548), 429-431.
Slaughter, S., & Rhoades, G. (2004). Academic Capitalism and the New Economy: Markets, State, and Higher Education. Johns Hopkins University Press.
Shanafelt, T. D., Hasan, O., Dyrbye, L. N., et al. (2015). Changes in burnout and satisfaction with work-life balance in physicians and the general US working population between 2011 and 2014. Mayo Clinic Proceedings, 90(12), 1600-1613.
Chisholm, K.I., Finelli, M.J. (2023). Enhancing research culture in academia: a spotlight on early career researchers. BMC Neurosci 24, 46. https://doi.org/10.1186/s12868-023-00816-1
Ingleby, E. (2021). Neoliberalism and Higher Education. In: Neoliberalism Across Education. Palgrave Studies on Global Policy and Critical Futures in Education. Palgrave Pivot, Cham. https://doi.org/10.1007/978-3-030-73962-1_6
Moher D, Naudet F, Cristea IA, Miedema F, Ioannidis JPA, Goodman SN (2018) Assessing scientists for hiring, promotion, and tenure. PLoS Biol 16(3): e2004089. https://doi.org/10.1371/journal.pbio.2004089
Altbach, P. G., Reisberg, L., & de Wit, H. (2020). Responding to Massification: Differentiation in Postsecondary Education Worldwide. SensePublishers Rotterdam, 2017
Let me know your thoughts: Are you seeing this trend in your own university or organization? How can we push back against it?
My name is Alexander Jung, and I am a tenured Associate Professor specializing in Machine Learning. With over 15 years of
experience in both research and education, I have dedicated my career to advancing the field of machine learning and mentoring the next generation of experts.

![The spectral decomposition of a normal matrix ${\bf A}$ provides an
orthonormal basis ${\bf u}^{(1)}, {\bf u}^{(2)}$. Applying ${\bf A}$
amounts to a scaling of the basis vectors by the eigenvalues
$\lambda_{1},\lambda_{2}$.[]{#fig:eigenvectors-length_dict
label="fig:eigenvectors-length_dict"}](../images/spectraldecomp_tikz.png) {#fig:eigenvectors-length_dict
width=”80%”}
{#fig:eigenvectors-length_dict
width=”80%”}![The pmf $p^{(x)}\left(\cdot\right)$ of a discrete random variable (RV)
$x$ taking values in the set $\mathcal{X}= {\star,\otimes}$. Three
datasets are also shown whose relative frequencies of data points match
this pmf exactly. Such datasets could arise as realizations of
independent and identically distributed (i.i.d.) random variables (RVs)
sharing the common pmf $p^{(x)}\left(\cdot\right)$. []{#fig_pmf_dict
label="fig_pmf_dict"}](../images/pmf_tikz.png) {#fig_pmf_dict
width=”80%”}
{#fig_pmf_dict
width=”80%”}